Gorosoft SpiderWeb
Intelligent web scraping and data analysis platform
A dual-mode platform combining visual recipe builder for business users with full Scrapy power for developers. Describe what you want to scrape in plain English and let the AI wizard handle the rest.
Key Features
Everything you need for web scraping at scale
From simple data extraction to complex crawling pipelines — SpiderWeb covers the full spectrum with an intuitive interface and powerful automation.
Dual-Mode Scraping
Visual recipe builder for business users who need point-and-click simplicity, plus full Scrapy integration for developers who want complete control over their spiders.
AI-Powered Wizard
Describe what you want to scrape in plain English. The AI wizard analyzes the target page, generates selectors, and builds a working recipe or Scrapy spider automatically.
Multi-Tenant Projects
Organize scraping tasks into projects with team collaboration. Role-based access control lets you manage who can create, edit, and run spiders across your organization.
Real-Time Monitoring
Watch your scraping jobs in real time via WebSocket connections. Live progress updates, item counts, error logs, and performance metrics — all streamed to your dashboard.
Anti-Detection Built-In
Browser automation with headless Chrome, automatic user-agent rotation, proxy support, request throttling, and CAPTCHA handling to keep your scrapers running smoothly.
Modular Deployment
Docker Compose profiles let you run only what you need — from a minimal single-node setup to a full distributed cluster with Celery workers and MongoDB sharding.
Preview
See SpiderWeb in action
A modern, responsive interface designed for productivity — from login to project management and live scraping dashboards.
Login Screen
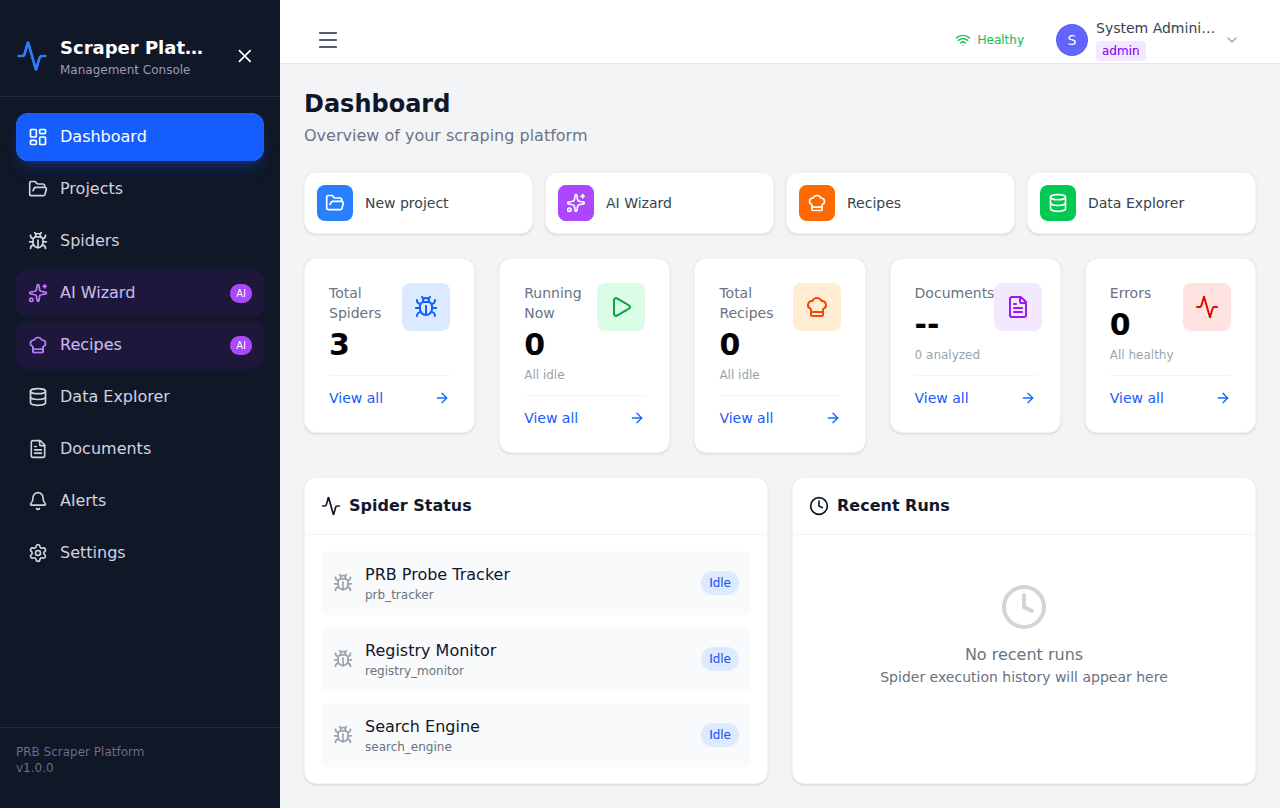
Scraping Dashboard
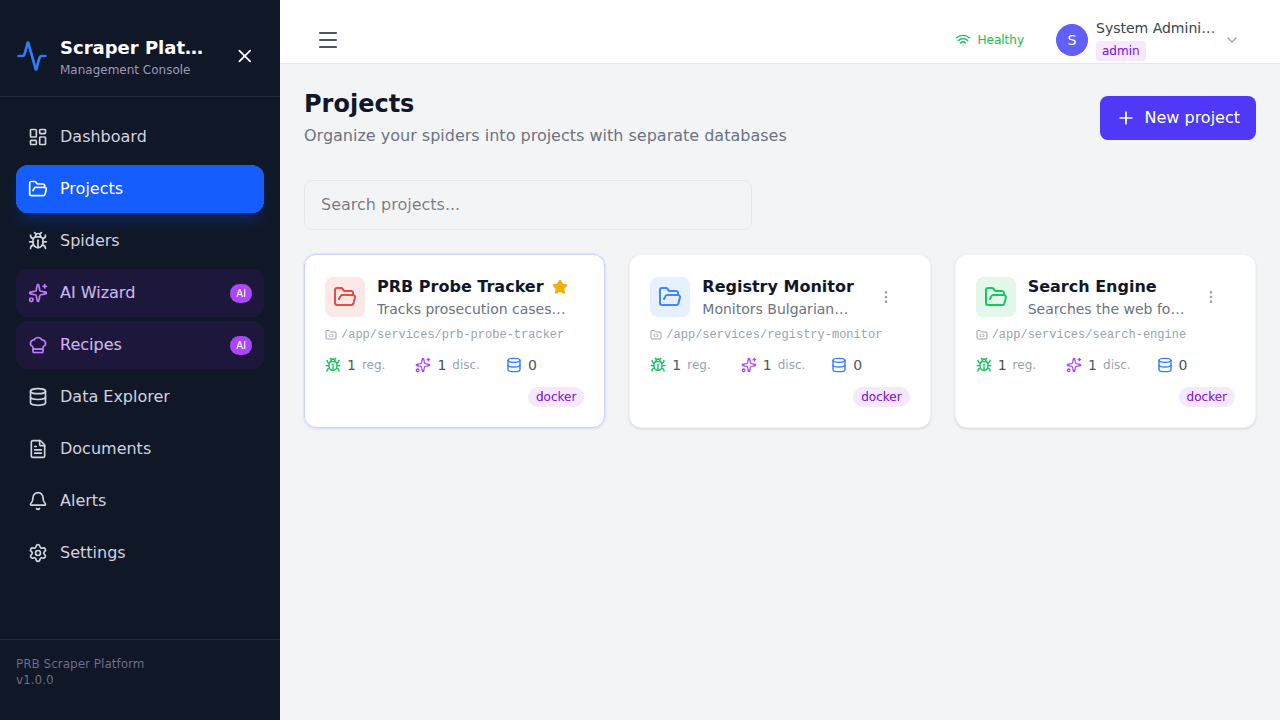
Project Management
Tech Stack
Built with modern, proven technologies
SpiderWeb leverages a battle-tested stack: FastAPI for the backend, React 19 for the frontend, MongoDB for flexible data storage, Scrapy for industrial-grade crawling, Docker for deployment, and Celery for distributed task execution.
Ready to start scraping smarter?
SpiderWeb is ready to deploy on your infrastructure. Request a demo to see the full platform in action and discuss how it fits your use case.